Terminal 3 — Denne posten er skrevet av malinux —
Dette er tredje post i terminalserien
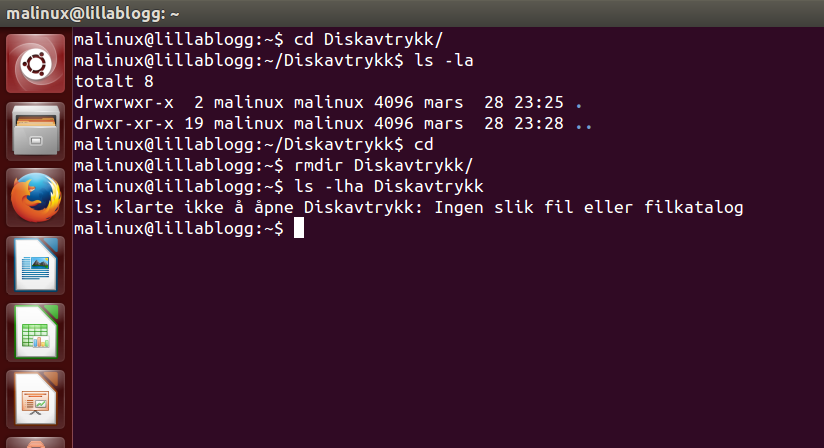
I forrige post, som ble litt lang, gikk jeg igjennom flere ls (liste)-eksempler, du (diskbruk), samt hvordan man oppretter og sletter mapper.
Jeg vil i denne tredje posten, vise eksempler på hvordan vi kan kopiere, slette og flytte mapper- og filer, samt hvordan vi kan søke igjennom innholdet i filer og mapper.
Før vi går helt i gang her, vil jeg tipse om kommandoen clear, som på norsk skulle være noe slikt som rens. Er det mye rart i terminalen, skriv clear, og du får en ren terminal igjen. En annen måte å rense terminalen på, er å trykke på ctrl + l (kontroll + l).
Kopiere filer
Jeg ønsker å kopiere fila "tekstfil1.txt" fra Nedlastinger til mappen Dokumenter.
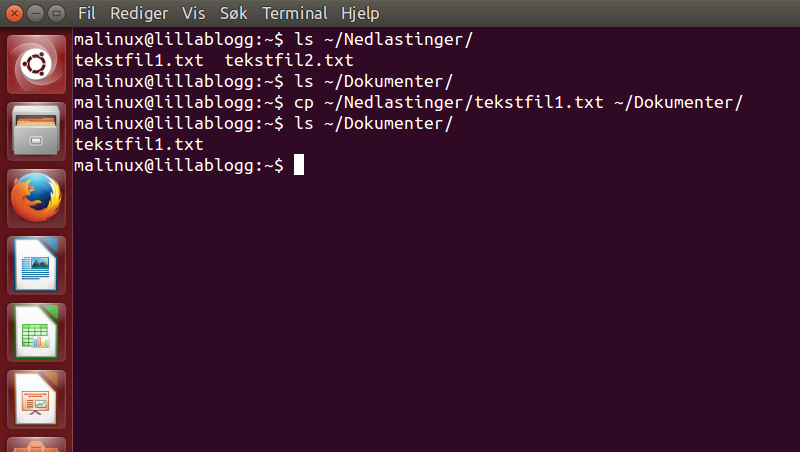
- cp - kopiere, eller copy på engelsk. Kommando som brukes til å kopiere filer og mapper.
- ~ - (Tilde-tegnet) Betyr hjem i *nix, og referer til $HOME og referer altså til hjemmemappen til brukeren du er logget inn som. For eksempel /home/malinux.
Vi ser nå at tekstfila ligger i Dokument-mappen. Siden vi har kopiert fila, så ligger den nå både i ~/Nedlastinger og i ~/Dokumenter.
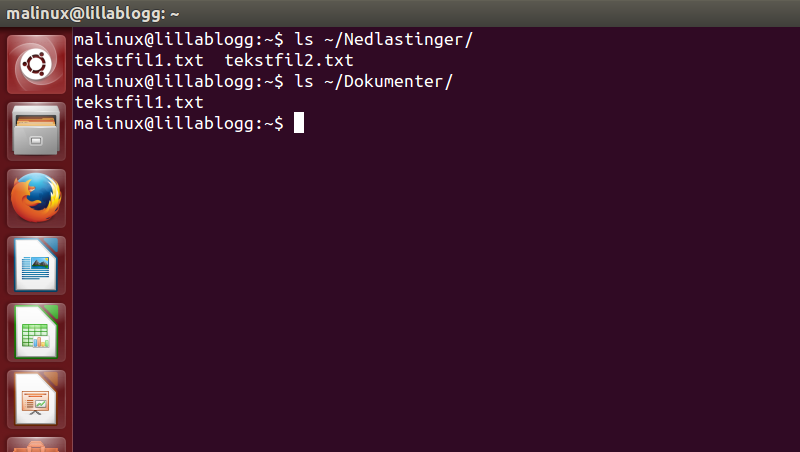
For å kun å ha tekstfila i Dokumenter, og ikke også i Nedlastingsmappa, så må fila slettes fra Nedlastingsmappa.
Man kan også gi nytt navn på en fil når man kopierer den. Dette er spesielt nyttig om du ønsker å redigere en konfigurasjonsfil. Da gjør man ikke noe krøll på originalfila i fall man vil gå tilbake til originalkonfigurasjonen.
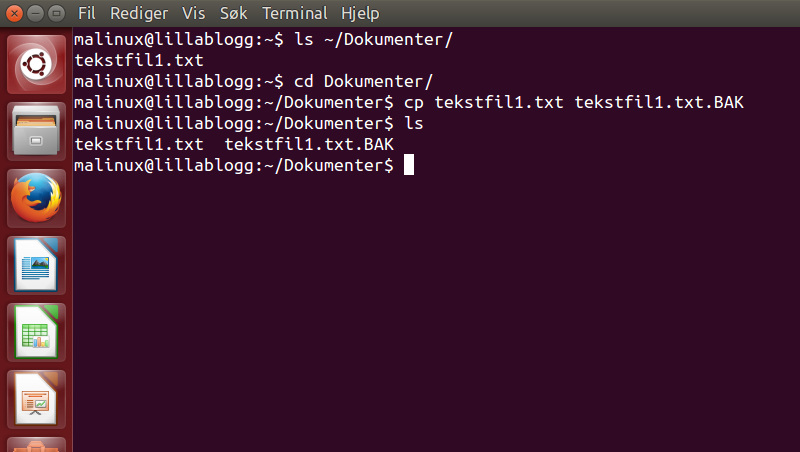
BAK er en forkortelse for backup, og det kunne like godt stått FORAN der, men BAK er litt mer beskrivende, og gjør det lettere å identifisere den som en backup. Man kan altså kalle kopien hva man vil, men det anbefales å bruke noe beskrivende.
Flytte filer
For å slippe å måtte slette filen fra opprinnelsesmappen etter den er kopiert til destinasjonsmappen, kan dette gjøres i én operasjon.
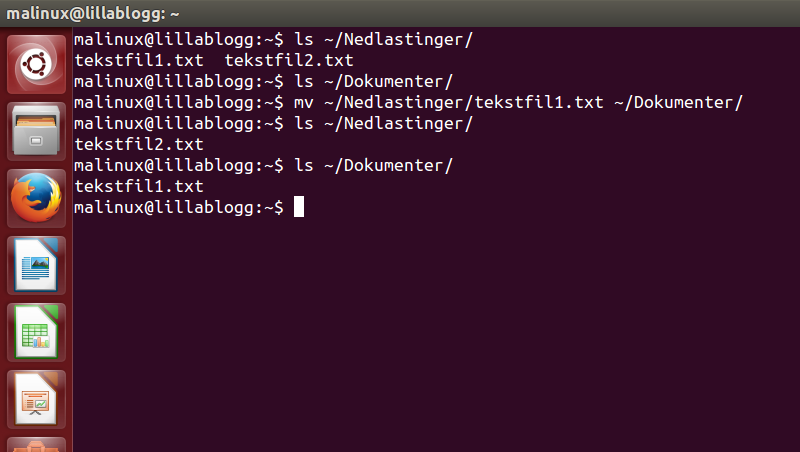
- mv - flytt, eller move på engelsk. Brukes for å flytte filer eller mapper fra destinasjon 1 til destinasjon 2.
Som vi ser er filen nå flyttet fra ~/Nedlastinger til ~/Dokumenter, fordi fila nå er borte fra ~/Nedlastinger, men finnes i ~/Dokumenter.
Kopiere mapper
Jeg ønsker å ta backup av Dokumentmappa. Nå vil jeg presisere at skal man ha virkelig backup, så bør jo den også lagres på et annet medium, enn der du har mappa fra før. Dette er bare et eksempel på selve kopieringsprosessen.
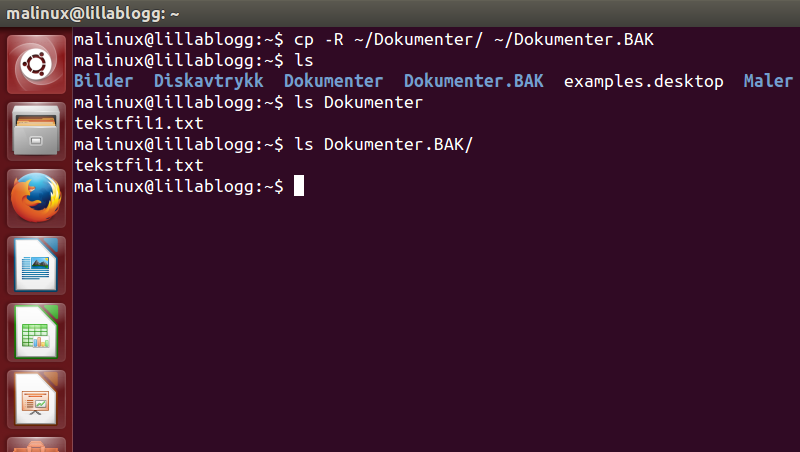
- cp -R - -R står for rekursiv, eller at at cp skal kopiere hele mappen, undermapper og all dens innhold, samt skjulte filer, til den nye destinasjonen.
Flytte mapper
I stedet for å kopiere mappen fra destinasjon 1 til destinasjon 2, så kan vi flytte mappen. Da vil den forsvinne fra destinasjon 1 og bli flyttet til destinasjon 2.
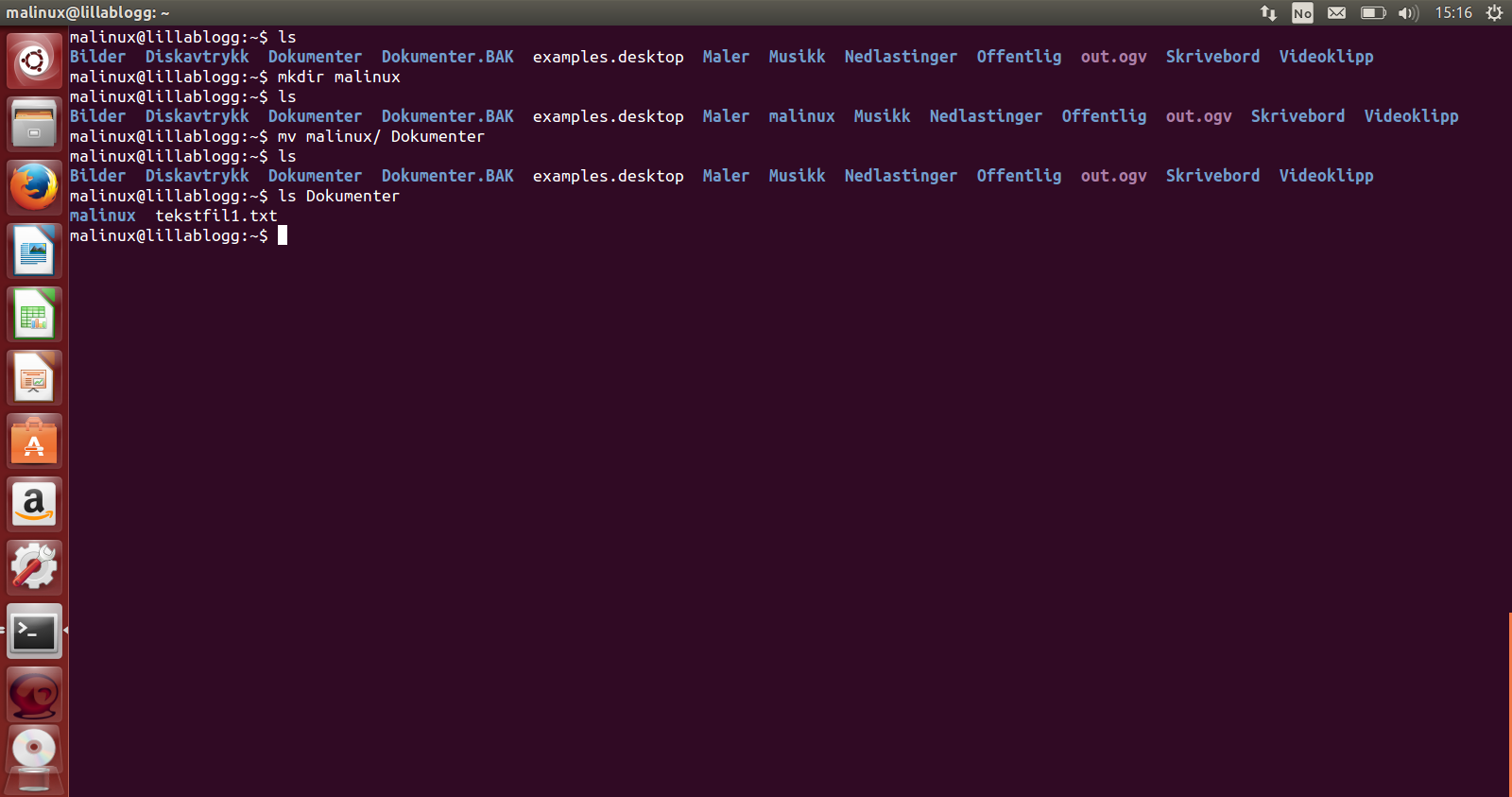
Vi ser at mappen og dens innhold ble flyttet, da mappen er borte fra hjemmeområdet, men finnes i mappen Dokumenter.
Søke i mapper
Når jeg vil undersøke om fila jeg leter i, ligger i en mappe, bruker jeg ls-kommandoen, som beskrevet i Terminal 1, men vi slenger på en | grep <søkestreng>
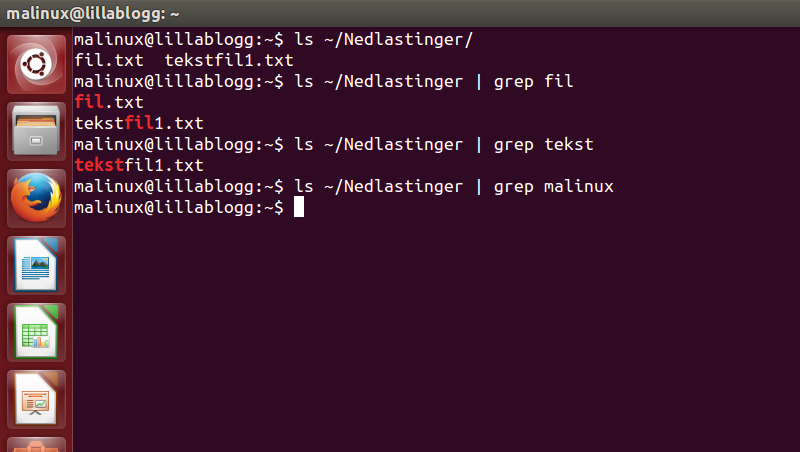
Vi ser at grep søker etter ord som starter på bokstavene vi la inn i søkestrengen, og at den ikke viser innhold, som ikke matcher søkestrengen vår.
Søke i og se innholdet i filer
Når jeg vil søke i eller se innholdet i filer, så brukes kommandoen cat
- cat - samler sammen innholdet i en fil og printer innholdet til terminalen.
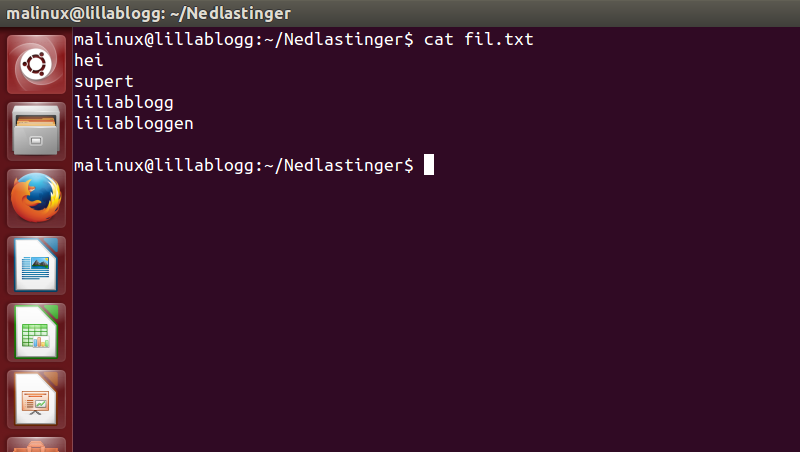
Om innholdet i fila er lenger enn terminalen, så kan vi også bruke | less, som også er beskrevet i Terminal 2.
med cat | grep <søkestreng> så kan vi søke etter og kun vise ordene vi leter etter slik:
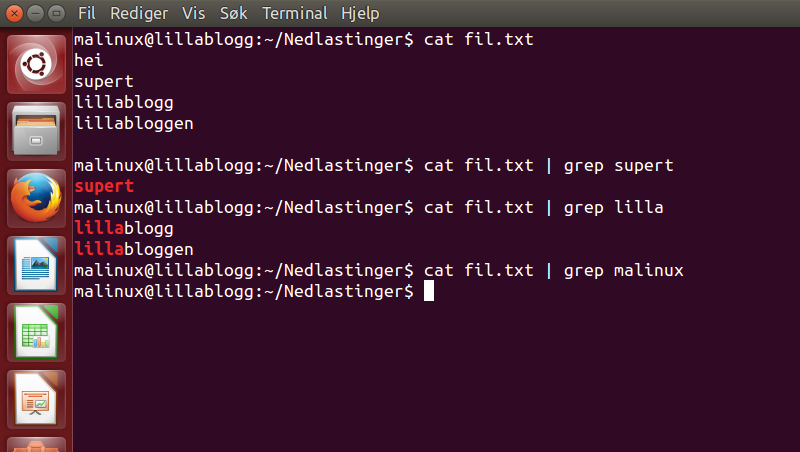
Om det vi søker etter, ikke finnes i fila, vil den ikke returnere noe, som vi ser når jeg prøvde å søke etter malinux i fila, men der var ingen malinux.
Oppsummering:
Kopiere mappe eller fil:
Brukes når vi ønsker å ha mappen eller fila på flere steder. For eksempel ved backup, eller om vi vil være tryggere på at innholdet er flyttet over på rett måte og ikke noe mangler, før man sletter mappene eller filene fra destinasjon 1.
Flytte mapper eller filer:
Gjør det raskere å flytte filer eller mapper, da man ikke trenger å slette fra destinasjon 1 etter man erferdig. Bakdelen er at vi ikke har filene liggende i destinasjon 1 om noe går galt under flyttingen.
Se innholdet i filer:
Bruk cat filnavn, eller cat filnavn | grep <søkestreng> for å vise det du søker etter, om det finnes i fila.
Kilder:
http://info.ee.surrey.ac.uk/Teaching/Unix/